Drawn to Scale announces Spire for Mongo
Cloud Technology for Data Intensive Computing
February 24, 2017Why We Chose MapR to build a Real-Time Database for Hadoop
March 29, 2017Drawn to Scale announces Spire for Mongo
Today, we’re announcing that we’ve ported MongoDB onto Spire as a platform. What this means is:
1. You can easily scale your MongoDB cluster to hundreds of terabytes
2. You don’t need to change a line of code in your app to make it scale
3. You can use ANSI SQL (yes, joins), Mongo queries, and Hadoop *on the same data*.
By changing the storage and execution engine behind Mongo, Spire also alleviates problems such as difficult backups, indexes being constrained by memory, using only a single index in queries, and the ‘global/collection lock’…as well as others. V1.0 of Spire for Mongo focuses on CRUD and Aggregations.
Spire for Mongo is available to Drawn to Scale beta customers. Sign up to become a beta user now.
Customers are our inspiration and Devrim from Koding says it best:
“Koding is exchanging ~15M messages a day and currently 90% of them read or write from MongoDB. Growing with this scale, hitting 1M users will mean a Mongo nightmare, which is not that far away from us. What Drawn to Scale is doing with Spire for Mongo will allow us to massively scale Koding to hundreds of terabytes of data, without changing our application code.” says Devrim Yasar, CEO of Koding.
Why did we do this?
We firmly believe SQL is the ‘Rosetta Stone’ of data … but many app developers, especially at rapidly growing startups, love the simplicity and speed of Mongo. It helps them develop apps quickly instead ohttp://web.archive.org/web/20130516181016/http://siliconangle.com/blog/2013/02/28/sql-is-the-rosetta-stone-of-big-data-says-bradford-stephens-drawn-to-scale/f building ORMs or hand-coding stored procedures.
Yet MongoDB is a sharded database, and not built for large-scale distributed environments. There are only a handful of multi-terabyte Mongo deployments. Therefore, when apps need to handle ‘Big Data’, developers find themselves rewriting their apps to use a sharded SQL db, or a NoSQL key-value store.
MongoQL is also great because unlike SQL, there is only one flavor. So we can support that version, and developers can effortlessly use both Spire and MongoDB aside each other without having to change app code.
How did we do this?
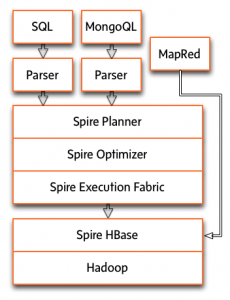 Something we have not mentioned: Spire was not built to be a distributed SQL database. Spire is a platform for *building* distributed databases. Every aspect of Spire is made to be distributed from the ground up: storage, schemas, indexing, execution, planning, optimiziation, etc. But they’re all abstracted from the query language. Our query execution engine has its own intermediate language that describes low-level actions (scan data, filter data, spool data, transport data to another node).
Something we have not mentioned: Spire was not built to be a distributed SQL database. Spire is a platform for *building* distributed databases. Every aspect of Spire is made to be distributed from the ground up: storage, schemas, indexing, execution, planning, optimiziation, etc. But they’re all abstracted from the query language. Our query execution engine has its own intermediate language that describes low-level actions (scan data, filter data, spool data, transport data to another node).
Since any query can be described with a handful of low-level actions, the only difference between a SQL query and a Mongo query is the parser and some storage metadata. Everything else, from optimization to execution, is exactly the same.
More tehcnical details and examples will be presented in the following weeks.
It comes back to Interface vs. Infrastructure. SQL and MongoQL are merely interfaces to data — the infrastructure running those queries is more important. MySQL and Mongo are both single-node/shardable infrastructures. They work fantastically and efficiently i3vidual server, but to maximize throughput and minimize latency in large clusters.
What does it mean?
If you’re a MongoDB user and you’re expecting to have hundreds of gigabytes to a few terabytes of data, stock Mongo is all you need. But if you find your resources being stretched, and you can’t add more users or features because it’ll bring the database down — Contact us and we’ll talk about how Spire can help you scale.